D1.5 Determine the impact of adding or removing data from a data set on a measure of central tendency, and describe how these changes alter the shape and distribution of the data.
Skill: Determining and Describing the Impact of Adding or Removing Data From a Data Set on a Measure of Central Tendency
Statistical measures, such as the mean, are used to describe a set of data. Statistical measures are presented as part of the fourth step in the inquiry process, interpreting the results, because they are another way of attributing meaning to the data and can provide information upon which to base a decision.
Different statistical measures are commonly used in data management. Those studied in the junior grades are the range, the mode, the median, and the mean. Students need to have a clear understanding of what each represents in order to choose, identify, and use them appropriately.
Source: translated from Guide d’enseignement efficace des mathématiques, de la 4e à la 6e année, Traitement des données et probabilité, p. 107.
They will then be able to identify and describe how adding or removing data from a set may or may not affect the graphical representation of the data.
Knowledge: Range
In examining a set of quantitative data, we are often inclined to spot the maximum value and the minimum value. These extreme values define the interval within which the data are situated. In data management, the size of this interval is called the range. The range is the number that corresponds to the difference between the maximum value and minimum value of the data and gives a measure of the variability of the data. If the range is small, there is little variability, since the data are grouped within a small interval. If the range is large, there is a lot of variability, since the data is spread over a larger interval. Note that range is not a measure of central tendency.
Source: translated from Guide d’enseignement efficace des mathématiques, de la 4e à la 6e année, Traitement des données et probabilité, p. 107.
Example
Temperature in July (°C)
25 29 30 30 31 31 32 34 34 35 38 38 42
For this data set, the range is 17 (42 - 25).
Knowledge: Measures Of Central Tendency (Mode, Median, Mean)
Each of the measures of central tendency is a way of describing a set of data with a single value (number). In some situations, only one of these measures makes sense, but in others, two or three are meaningful, even if they are different.
Source: adapted from Making Math Meaningful, Marian Small, p. 574.
Mode
The mode of a set of data represents the value or category having the highest frequency. The mode is particularly significant in survey settings where it is necessary to determine what is most popular, most sold, most frequent, etc. As the examples below illustrate, it is possible to determine the mode of a quantitative or qualitative set of data.
Example 1
The table below shows the number of children in the families of students in a class. The most frequent number is 2, which indicates that there are more families with two children than any other number of children. The mode of this quantitative set of data is 2 children per family.
Number of Children in the Families of the Students in the Class
| Number of Children in the Family | Number of Students |
|---|---|
| 1 | 3 |
| 2 | 12 |
| 3 | 6 |
| 4 | 3 |
| more than 4 | 2 |
Example 2
The graph below shows the favourite colours of the students in the class. To determine the mode of this qualitative data, we need to look at the length of the bars. The red and blue bars are of equal length and are longer than all the others. So in this case, there are two modes, red and blue.
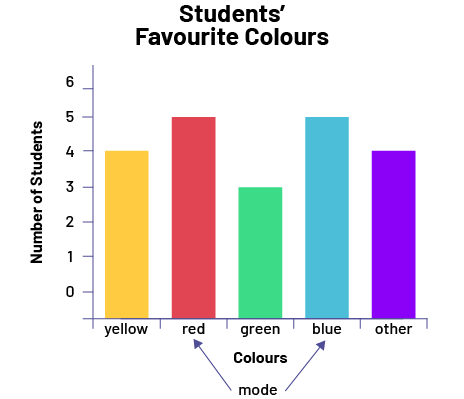 Image A bar graph is titled " Students' favorite colours". The horizontal axis corresponds to the colours, while the vertical axis, graduated from zero to six, corresponds to the number of students. The yellow bar, representing the same colour, rises to four. The red bar rises to five. The green bar rises to three. The blue bar rises to five. And a purple bar, which represents the other colours, rises to four. Below the horizontal axis, the word "mode" points to red and blue with two arrows.
Image A bar graph is titled " Students' favorite colours". The horizontal axis corresponds to the colours, while the vertical axis, graduated from zero to six, corresponds to the number of students. The yellow bar, representing the same colour, rises to four. The red bar rises to five. The green bar rises to three. The blue bar rises to five. And a purple bar, which represents the other colours, rises to four. Below the horizontal axis, the word "mode" points to red and blue with two arrows.
Example 3
The data below was recorded during a long jump competition.
- 1.04 m 1.06 m 1.12 m 1.13 m 1.16 m 1.19 m 1.22 m 1.28 m 1.36 m
Since all the values are different, there is no value with the highest frequency. This set of data has no mode. However, the values could be grouped into intervals, as in the table below. In such a case, the mode corresponds to the interval with the highest frequency, which is the interval from 1.10 m to 1.19 m.
Long Jumps
| Length (m) | Number of Students |
|---|---|
| 1.00 to 1.09 | 2 |
| 1.10 to 1.19 | 4 |
| 1.20 to 1.29 | 2 |
| 1.30 to 1.39 | 1 |
When using the mode to answer a question of interest or make a decision, it is important to consider the set of data. In some situations, the most frequent value or category may not be the one that makes the most sense of the data. It is important to encourage students to examine each situation closely before drawing conclusions based on the mode.
The following are examples of situations in which the appropriateness of using mode as a representative data value is evaluated:
- In example 1 above, the mode of 2 children per family seems to be fairly representative of the situation since there is a significant difference between this frequency and the others.
- In example 2 above, not only are there two modes (red and blue), but the difference between their frequency and the others is not very large. It is therefore difficult to conclude that these two modes represent a strong colour preference. In this case, it would be better to mention that red and blue are slightly more popular, but that yellow follows closely behind.
- In the stem and leaf plot below, the mode is 72 heartbeats per minute. This number is also in the interval (70 to 79) that has the most data. Therefore, it represents this data set well.
Number of Heartbeats per Minute of Students in the Class
| 6 | 3 5 5 8 9 |
| 7 | 1 1 2 2 2 2 2 4 5 7 7 |
| 8 | 2 3 6 |
| 9 | 1 2 |
| 10 | 8 |
- From the line plot below, the mode corresponds to 60 heartbeats per minute. This number is far from the interval that contains most of the data points (69 to 77). Also, the range of the data (29) is large, and each data value appears only once, twice, or three times, so it would be best to not use the mode to draw a conclusion about this set of data.
 Image The Number line is titled "Students’ Number of Heartbeats Per Minute". It is graduated from 60 to 90. With an arrow, the word "mode" points to the number 60. The numbers that have no X's are: 61, 63, 64, 65, 66, 68, 78, 79, 80, 82, 83, 84, 86, 87, 88, and 90. The numbers 62, 67, 69, 70, 71, 74, 76, 77, 81, 85 and 89 have an X. The numbers 72, 73 and 64 have two X's. The number 60 has three X's.
Image The Number line is titled "Students’ Number of Heartbeats Per Minute". It is graduated from 60 to 90. With an arrow, the word "mode" points to the number 60. The numbers that have no X's are: 61, 63, 64, 65, 66, 68, 78, 79, 80, 82, 83, 84, 86, 87, 88, and 90. The numbers 62, 67, 69, 70, 71, 74, 76, 77, 81, 85 and 89 have an X. The numbers 72, 73 and 64 have two X's. The number 60 has three X's.
Source: translated from Guide d’enseignement efficace des mathématiques, de la 4e à la 6e année, Traitement des données et probabilité, p. 108-111.
Median
The median of a set of data is the number in the middle of this set. This means that there are the same number of values on either side of the median. To determine the median of an odd number of data, simply place them in ascending or descending order and determine the number in the middle. In the case of an even number of data, the median is the number that is halfway between the two numbers in the middle. In such cases, the median could be a number that is not part of the set of data.
Example 1
The following data was recorded during a long jump competition.
1.04 m; 1.06 m; 1.12 m; 1.13 m; 1.16 m; 1.19 m; 1.22 m; 1.28 m; 1.36 m
There are nine data values and they are placed in ascending order, so the median of these data is the fifth, which is 1.16 m. Notice that there are the same number of data (four) on each side of the median.
Example 2
The stem-and-leaf plot below shows 22 data values placed in ascending order. Two data values are in the middle, the 11th and 12th. Note that there are the same number of values (ten) on either side of these two numbers. Since these two values correspond to 72 heartbeats per minute, this is the value assigned to the median.
| Number of Heartbeats per Minute of Students in the Class | |
|---|---|
| 6 | 3 5 5 8 9 |
| 7 | 1 1 2 2 2 2 2 4 5 7 7 |
| 8 | 2 3 6 |
| 9 | 1 2 |
| 10 | 8 |
Example 3
At a fundraiser for their sports team, 10 students sold boxes of chocolate. Here are the numbers of boxes sold:
15, 12, 11, 10, 10, 8, 7, 6, 5, 5
The 5th and 6th values are in the centre of this set of ten data values placed in descending order and these two values, 10 and 8, are different. The median then is 9, since 9 is halfway between 8 and 10. Despite the fact that this median is not part of the set of data items, we can see that there are five values on either side of 9.
Example 4
The stem-and-leaf plot below shows the maximum daily temperatures for a city during the month of June, in degrees Celsius.
| 1 | 2 | 4 | 6 | 6 | 7 | 8 | 9 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 0 | 0 | 1 | 1 | 1 | 1 | 3 | 4 | 5 | 5 | 6 | 6 | 7 | 7 | 8 | 8 | 9 | 9 | 9 |
| 3 | 0 | 2 | 3 | 3 |
Students place the numbers on a strip of paper and discover that there are two numbers in the middle, 24 and 25. Also, there are no integers halfway between 24 and 25. Students can then use their knowledge of decimal numbers to determine that it is 24.5 that is halfway between 24 and 25. The median of this data set is therefore 24.5 C.

The median is an important statistical measure that is commonly used in many situations. Since the median indicates the value at the centre of an ordered set of data, it is possible to place all other values in relation to it. For example, the student in Example 1 who successfully jumped 1.28 m has jumped farther than the median of 1.16 m and, therefore, farther than most of the other jumps.
Before using the median to make decisions, it is important to consider the range of the data because the median does not take into account extreme values. In Example 3, the approximate number of boxes that were sold by each student is represented by the median. The median number of boxes sold is 9 and the data range is from 5 to 15 boxes. The range of the data is small, and the median of 9 is almost halfway between the maximum and the minimum value. Therefore, it can be assumed that each student sold about 9 boxes and concluded that the 10 students sold about 90 boxes.
Now imagine a situation with the same data, except the largest number of boxes sold is 75 instead of 15. The median is still 9 boxes, but the range is very large. Also, the median is not at all halfway between the maximum and minimum values, so one could not assume that each student sold about 9 boxes, as in the previous situation, nor conclude that the 10 students sold about 90 boxes in total.
Teachers can help students deepen their understanding of the concept of median by modifying some of the situations they have already studied, as shown in the following example.
Example 5
Let's go back to Example 3 and add a variant as follows:
At a fundraiser for their sports team, 10 students sold boxes of chocolate. Here are the numbers of boxes sold.
15, 12, 11, 10, 10, 8, 7, 6, 5, 5
However, three other students have not yet reported their number of boxes sold. If the goal was to obtain a median number of eight boxes sold, what data set corresponding to the sales of the 13 students could meet this goal?
Here are two examples of possible answers.
15, 12, 11, 10, 10, 8, 8, 7, 7, 6, 5, 5, 4
15, 12, 11, 10, 10, 9, 8, 7, 6, 5, 5, 4, 3
If we add as a condition that the mode of the data set also corresponds to eight boxes, students could give the following answer.
15, 12, 11, 10, 10, 8, 8, 8, 7, 6, 5, 5, 4
Source: translated from Guide d’enseignement efficace des mathématiques, de la 4e à la 6e année, Traitement des données et probabilité, p. 111-115.
Mean
In mathematics, the mean has a precise meaning; it corresponds to the value resulting from an equal-share division. For example, if 5 friends have collected $5, $7, $8 and $8 respectively and they pool these amounts to share them equally, each will receive $7. The mean of the amounts collected is therefore equal to $7. In more advanced mathematics, this mean is called the arithmetic mean. Other means exist (for example, geometric mean, harmonic mean ), but they are not studied in the intermediate grades. Educators should focus on understanding the concept of mean rather than memorizing the usual algorithm (sum of the data divided by the number of data). To do this, they should provide students with activities that use the equal-share model or the balance model between the sum of the shortages (differences between the mean and the data that are less than the mean) and the sum of the surpluses (differences between the mean and the data that are greater than the mean). Otherwise, students gain only a limited understanding of the concept of mean.
Equal Share
The examples below show different situations that use the equal-share model and help develop a good understanding of the concept of mean. The equal-share model can be used to determine a mean without having to use the standard algorithm.
Example 1
< >Amir, Bruno, Carla, Denis and Elmira went fishing and caught 2, 2, 3, 3 and 10 fish respectively. Determine the mean of the number of fish caught.< >
To determine the mean of the number of fish caught, students can determine how many fish each person would have if the fish were evenly distributed. They can first illustrate the initial situation as follows.
 Image Title of the example: Before sharing. Images of goldfish are stacked above the names of 5 students. Amir has two fish, Bruno has two fish, Carla has 3 fish, Denis has 3 fish, and Elmira has 10 fish.
Image Title of the example: Before sharing. Images of goldfish are stacked above the names of 5 students. Amir has two fish, Bruno has two fish, Carla has 3 fish, Denis has 3 fish, and Elmira has 10 fish.
Then, the students divide the fish: Elmira gives 2 fish to Amir, 2 fish to Bruno, 1 fish to Carla and 1 fish to Denis.

After sharing, each person has 4 fish, so students can conclude that, on average, the 5 friends caught 4 fish each. The mean is 4.

In order to deepen the concept of mean, it is important to give students the opportunity to reverse the process by asking them to create a set of data with a given mean. This reinforces the concept of mean as the result of equal sharing.
Example 2
Six students in a class determined that they had, on average, 5 pens each. What might be a possible distribution of pens among these six students?
Since the 6 students have an average of 5 pens each, each student would have 5 pens after the equal share.

This gives a total of 30 pens (6 x 5). The 6 students can then divide the 30 pens among themselves as they see fit. Regardless of the division chosen, the mean value of 5 (average of five pens per student) will be maintained. Here is an example of a possible division:
 Image Six columns of pens are lined up side by side. The first column has 5 pens, the second column has 7 pens, the third column has 4 pens, the fourth column has three pens, the fifth column has 7 pens and the sixth column has 4 pens.
Image Six columns of pens are lined up side by side. The first column has 5 pens, the second column has 7 pens, the third column has 4 pens, the fourth column has three pens, the fifth column has 7 pens and the sixth column has 4 pens.
There is always a total of 30 pens.
One can use the equal share model to develop an understanding of the usual algorithm as illustrated in the example. The model indeed makes sense of the usual algorithm, as it demonstrates the idea of grouping pens and then sharing them among friends (the sum of the values divided by the number of values).
Example 3
Annie, Bahéya, Carl, Daniel and Eva have $5, $6, $6, $8 and $10 respectively. How much money does each person have on average?
First, the money is pooled to find that there is a total of $35. This is equal to $5 + $6 + $6 + $8 + $10 = $35. The money is then divided equally and each person receives $7, which is equal to $35 ÷ 5 = $7.
 Image At the top of Example 3, five student names each have a few red chips. Annie has 5 chips, Bahéya has 6 chips, Carl has 6 chips, Daniel has 8 chips and Eva has 10 chips. Under the names it says: Altogether, 5 dollars plus 6 dollars plus 6 dollars plus 8 dollars plus 10 dollars equals 35 dollars. An arrow points to the middle of Example 3 where all the chips are pooled for a total of 35. Below the pile of 35 chips, it says: Sharing, 35 divided by 5 equals 7 dollars. Under the cluster of 35 chips, 5 arrows point down to each of the names that are repeated and where the chips are redistributed equally. Annie, Bahéya, Carl, Daniel and Eva each have 7 chips.
Image At the top of Example 3, five student names each have a few red chips. Annie has 5 chips, Bahéya has 6 chips, Carl has 6 chips, Daniel has 8 chips and Eva has 10 chips. Under the names it says: Altogether, 5 dollars plus 6 dollars plus 6 dollars plus 8 dollars plus 10 dollars equals 35 dollars. An arrow points to the middle of Example 3 where all the chips are pooled for a total of 35. Below the pile of 35 chips, it says: Sharing, 35 divided by 5 equals 7 dollars. Under the cluster of 35 chips, 5 arrows point down to each of the names that are repeated and where the chips are redistributed equally. Annie, Bahéya, Carl, Daniel and Eva each have 7 chips.
Teachers can use this example to emphasize to students that the mean of a set of data is not necessarily a number that is part of that set. For some students, this idea is difficult to understand.
Another way to help students develop an understanding of the concept of a mean is to ask them to identify a missing piece of data for a set of data to have a particular mean.
Example 4
Five students are raising money. If the students raise an average of $25 each, they win tickets to a hockey game. On Monday, 4 of the 5 students meet and find that they have raised $29, $21, $31 and $13 respectively. What is the minimum amount of money that Suzie, the 5th student, must have raised if the group is to win the hockey tickets?
Students who have only learned to use the usual algorithm for determining the mean are often unable to answer this type of question because they are not able to adapt a learned procedure to the circumstances because they do not understand it. Students who have developed an understanding of the concept of mean as a share are better equipped to solve this type of problem. Here is an exchange that the four students might have to determine the amount of money Suzie would have to collect.
Student 1: We need to get an average of $25, which means that if we split the money equally between us, we will each have $25. I raised $29, so I can share $4 with you.
Student 2: I only got $21, so I'm $4 short.
Student 3: I have an extra $6 because I collected $31.
Student 4: I'm sorry. I was sick this weekend and only raised $13. I am $12 short.
Student 1: Let's use the idea of sharing to help us determine how much money Suzie will need to have collected to achieve an average of $25.
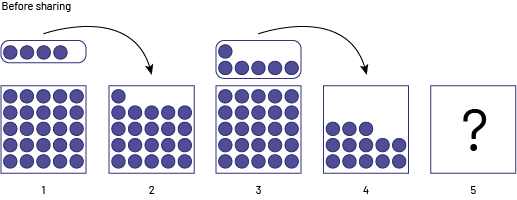 Image Under the title "Before Sharing", five boxes are lined up side by side. The first box contains 25 chips. Above it, a set of 4 chips is linked to the second box by an arrow. The second box contains 21 chips. The third box contains 25 chips, and above it, a set of 6 chips points to the fourth box with an arrow. The fourth box contains 13 chips. The fifth box contains no chips, but has a question mark.
Image Under the title "Before Sharing", five boxes are lined up side by side. The first box contains 25 chips. Above it, a set of 4 chips is linked to the second box by an arrow. The second box contains 21 chips. The third box contains 25 chips, and above it, a set of 6 chips points to the fourth box with an arrow. The fourth box contains 13 chips. The fifth box contains no chips, but has a question mark.
As a result of the sharing, the first three students each have $25, but the fourth student is $6 short of $25, so Suzie must bring in the missing $6 in addition to her $25, so she must have collected $31.
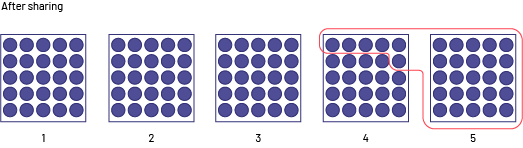 Image Under the title "After Sharing", five boxes lined up side by side each have 25 chips. With a red border, the 25 chips from the fifth box and six chips from the fourth box are grouped into a set.
Image Under the title "After Sharing", five boxes lined up side by side each have 25 chips. With a red border, the 25 chips from the fifth box and six chips from the fourth box are grouped into a set.
Balance Between the Sum of the Surpluses and the Sum of the Shortages
Teachers can also help students develop an understanding of the concept of mean by presenting them with situations that involve the surplus/shortage balance model. This model, a variation of the sharing model, is perhaps less familiar. It is based on the idea that if, for example, a group of students has an average number of tokens, some students might have fewer than the average while others might have more. However, the total of what the students have less of must equal the total of what the students have more of. The two examples below illustrate this idea.
Example 1
Five people have four tokens each. One of them gives two tokens to another.
 Image Five sets of four red chips are lined up side by side. In the second set, two of the chips are circled. An arrow connects them to the fourth set of chips.
Image Five sets of four red chips are lined up side by side. In the second set, two of the chips are circled. An arrow connects them to the fourth set of chips.
Despite this exchange, the mean is still four tokens per friend. However, we see that, compared to the mean, one friend has a shortage of two tokens, while another has a surplus of two tokens. The shortage equals the surplus, which is normal, since one friend has lost what another has gained. Moreover, we can reverse the situation, since the surplus of two tokens could be used to make up for the shortage of two tokens so that everyone has four tokens.
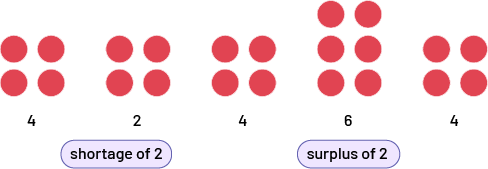 Image Five sets of red chips are lined up side by side. The first set contains four chips. The second set contains two chips, it is also written "lack of two". The third set contains 4 chips. The fourth set contains 6 chips, it is also written " surplus of two ". And the fifth set contains 4 chips.
Image Five sets of red chips are lined up side by side. The first set contains four chips. The second set contains two chips, it is also written "lack of two". The third set contains 4 chips. The fourth set contains 6 chips, it is also written " surplus of two ". And the fifth set contains 4 chips.
The example shows that this situation is still true, even after several exchanges.
Example 2
Five people have 4 tokens each. Annie gives 1 token to Carl and 1 token to Daniel. Bahéya gives 1 token to Carl and 2 tokens to Eva.
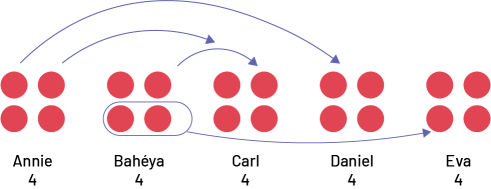 Image Five sets of 4 red chips lined up side by side have the following names respectively: Annie, Bahéya, Carl, Daniel, Eva. Above the first set, arrows point to the third and fourth sets respectively. On the second set, an arrow points to the third set; two chips are surrounded and linked to the fifth set by an arrow.
Image Five sets of 4 red chips lined up side by side have the following names respectively: Annie, Bahéya, Carl, Daniel, Eva. Above the first set, arrows point to the third and fourth sets respectively. On the second set, an arrow points to the third set; two chips are surrounded and linked to the fifth set by an arrow.
The mean is still 4 tokens per person. However, compared to the mean, Annie has a shortage of 2 tokens, Bahéya has a shortage of 3 tokens, Carl has a surplus of 2 tokens, Daniel has a surplus of 1 token, and Eva has a surplus of 2 tokens. Therefore, compared to the mean, the sum of the shortages is 5 tokens (2 + 3) and the sum of the surpluses is 5 tokens (2 + 1 + 2). We can see that the sum of the shortages equals the sum of the surpluses.
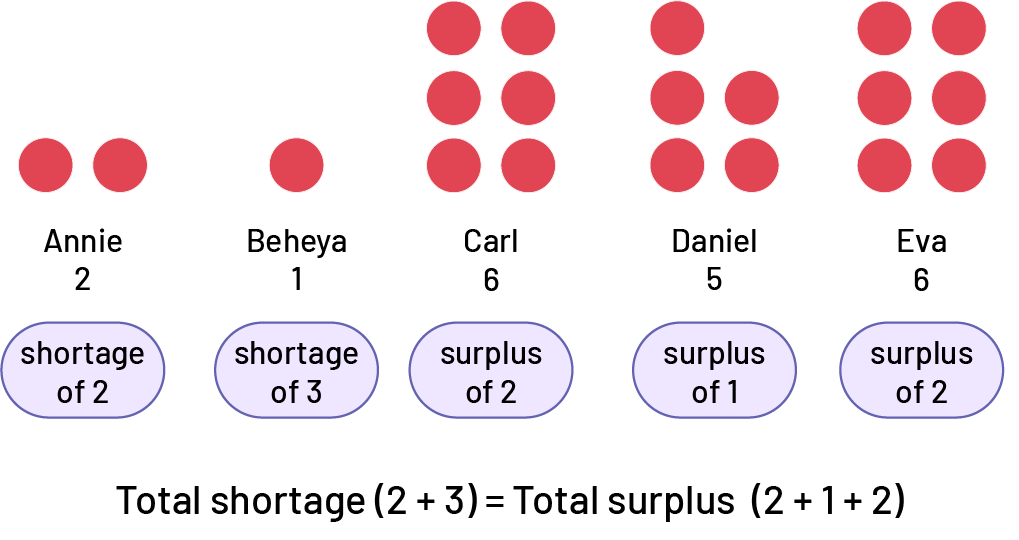 Image Five sets of red chips lined up side by side have the following names respectively: Annie, Bahéya, Carl, Daniel, Eva. The first set contains two chips and indicates a lack of two. The second set contains one chip and indicates a lack of three. The third set contains 6 chips and indicates a surplus of two. The fourth set contains five chips and indicates a surplus of one. And the fifth set contains 6 chips and indicates a surplus of two. Below the sets appears the following equation: sum of the lacks opening parenthesis two plus three closing parenthesis equals sum of the surpluses opening parenthesis two plus one plus two closing parenthesis.
Image Five sets of red chips lined up side by side have the following names respectively: Annie, Bahéya, Carl, Daniel, Eva. The first set contains two chips and indicates a lack of two. The second set contains one chip and indicates a lack of three. The third set contains 6 chips and indicates a surplus of two. The fourth set contains five chips and indicates a surplus of one. And the fifth set contains 6 chips and indicates a surplus of two. Below the sets appears the following equation: sum of the lacks opening parenthesis two plus three closing parenthesis equals sum of the surpluses opening parenthesis two plus one plus two closing parenthesis.
The surplus-shortage equilibrium model can be used to solve a variety of problems involving the mean. The situation below, presented in Example 3 of the Equal Share section above and solved using the sharing model, can just as easily be solved using the surplus-shortage equilibrium model.
Example 3
Five students are raising money. If the students raise a mean of $25 each, they win tickets to a hockey game. On Monday, 4 of the 5 students meet and find that they have raised $29, $21, $31 and $13 respectively. What is the minimum amount of money that Suzie, the 5th student, must have raised if the group is to win the hockey tickets?
First, look at each amount of money in relation to the mean of $25, and then determine the surplus or shortage.
29: $4 surplus
21: $4 shortage
31: $6 surplus
13: $12 shortage
Next, determine the sum of the surpluses and the sum of the shortages.

These two amounts are not equal, so to balance them out, we need an extra $6 ($16 - $10), so Suzie must have collected $25 + $6, or $31.
Once students have developed a good understanding of the concept of mean, they are able to:
- determine the mean of a data set and understand the relationship between the data and the mean;
- create a set of data that corresponds to a particular mean and understand that the same mean can come from more than one set of data;
- determine a missing data item from a set of data to obtain a particular mean and understand the effect on the mean of adding new data.
Only when this understanding is achieved should students be introduced to the usual algorithm for calculating the mean, which is:

Note that focusing on conceptual understanding of the mean avoids some of the following conceptual errors that were identified by Konold and Higgins (2003, p. 203-204):
- some students confuse the mean with the mode, in other words, they associate it with the most frequent value;
- some students associate the mean only with an algorithm, which makes it difficult for them to create a data set that corresponds to a particular mean;
- some students mistake the mean for the median, that is, they associate it with the value in the center of the set of data.
Even with a good understanding of statistical measures, it is not always easy to choose the best measure for a given situation in a decision-making context, so in the junior grades it is best to stick to simple situations.
Example
Matthew wants to negotiate with his parents for an increase in the amount of weekly allowance they give him. Knowing that he cannot simply ask for an increase without good reason, he decides to survey his fellow students to find out how much allowance they receive each week. He organizes the data collected on a line plot.
 Image The number line shows weekly amounts of pocket money in dollars, with "X's". At zero, there are four X's. At one, there is one "X". At one and a half, there are two X's. At two, there are two X's. At two and a half, there is an "X". At three, there is an "X". At three and a half, there are four X's. At four, there are five X's. At four and a half, there are four "X's". At five, there are five X's. At five and a half, there are two "X's". At six, there are four "X's". At six and a half, there are no "X's". At seven, there is one "X". At seven and a half, there is no "X". At eight, there is an "X". At eight and a half, nine and nine and a half, there is no "X". And at ten, there are six X's.
Image The number line shows weekly amounts of pocket money in dollars, with "X's". At zero, there are four X's. At one, there is one "X". At one and a half, there are two X's. At two, there are two X's. At two and a half, there is an "X". At three, there is an "X". At three and a half, there are four X's. At four, there are five X's. At four and a half, there are four "X's". At five, there are five X's. At five and a half, there are two "X's". At six, there are four "X's". At six and a half, there are no "X's". At seven, there is one "X". At seven and a half, there is no "X". At eight, there is an "X". At eight and a half, nine and nine and a half, there is no "X". And at ten, there are six X's.
Matthew then analyzes this data to choose a value on which to base his arguments for an increase. He finds that $10 is the most common value. He goes to his father and explains that his survey shows that more students receive $10 in spending money than any other amount.
His father finds this amount rather high and asks to see the set of data. After reviewing it, he explains to Matthew that because of the distribution of the data, mode is not the best measure to represent this data. Then he determines that the mean of the amounts allocated is $4.66 and tells Matthew that this amount seems more appropriate.
A bit disappointed, Matthew calculates the median and finds that it is $4.50. He understands that in this situation, both the mean and the median are good measures to represent the data, but since the median is lower than the mean, he decides that it is not to his advantage to use it.
Source: translated from Guide d’enseignement efficace des mathématiques, de la 4e à la 6e année, Traitement des données et probabilité, p. 115-125.